Chapter 9 Summary
The Bayesian Idea
- Thus far, learning a parametric model amounts to somehow finding a parameter value
that best fits the training data. - With the Bayesian approach, learning data amounts to finding hte distribution of the parameter values
conditioned on the observed training data - - The prediction is a distribution
instead of a single value. - With the Bayesian approach, the parameters of any model are consistently treated as being random variables.
- Learning amounts to computing the distribution of
conditional on the training data, denoted since we omit . - The computation is done using joint distribution factorisation and bayes theorem.
- By the laws of probabilities,
can be written as:
- Training a parametric model amounts to conditioning
on - . - After training, the model can be used to compute predictions - a matter of computing distribution
rather than a point prediction, for a given test input .
- Here
encodes the distribution of the test data output in which the corresponding input is omitted in the notation. - The other elements involved in the Bayesian approach are traditionally given the names:
- prior - posterior - posterior predictive (likelihood)
Representation of Beliefs.
- The prior represents our beliefs about a
before any data has been observed. - The likelihood
defines how data relates to the parameter - Using Bayes theorem, we update the belief about
to the posterior which also takes the observed data into account.
- Using Bayes theorem, we update the belief about
- These distributions represent the uncertainty about the parameter
before and after observing the data .
- The Bayesian approach is less prone to overfitting when compared to the maximum-likelihood based approach.
- With the maximum likelihood framework, obtain a single value
and use that to make our prediction according to - With the Bayesian distribution, obtained an entire distribution
representing the different hypotheses for the value of our model parameters.
- With the maximum likelihood framework, obtain a single value
- In small datasets, the uncertainty seen the posterior
represents how much (or little) can be said about from the presumably limited information in under the assumed conditions. - The posterior
is a combination of the prior belief and the information about carried by through the likelihood - Without a meaningful prior
, the posterior is not meaningful either.
- Without a meaningful prior
Bayesian Linear Regression
- Let
denote a q-dimensional multivariate Gaussian random vector . - The multivariate Gaussian distribution is parameterized by a
-dimensional mean vector and a covariance matrix .
- The covariance matrix is a real-valued positive semidefinite matrix - a symmetric matrix with nonnegative eigenvalues.
- The covariance matrix is positive definite if all eigenvalues are positive.As a shorthand, we write
or . - The expected value of
is and the variance of is . - The covariance between
is .
From Chapter 3, the linear regression model is given by:
- This expression is for one output point
, and thus the vector for all training outputs is denoted as:
- In the last step, use the fact that
-dimensional Gaussian random vector with diagonal covariance matrix is equivalent to scalar Gaussian random variables. - With the Bayesian approach, there is also a need for a prior
for the unknown parameters . - In Bayesian linear regression, the prior distribution is most often chosen as a linear regression with mean
covariance (for example, )
- The choice of this is motivated by the fact that it simplifies the computation for linear regression.
- We now need to compute the posterior distribution
- From Equation 9.10, we can also derive the posterior prediction for
:
- We can also compute the posterior predictive for
Connection to Regularised Linear Regression
- The main feature of Bayesian approach is that it provides a full distribution
for the parameters , rather than a single point estimate. - The MAP estimate and the L2 regularised estimate of
are identical for some value of .
The Gaussian Process
- Instead of considering the parameters
as random variables, we can consider the function as a random variable and compute the posterior distribution . - The Gaussian Process is a type of stochastic process; a generalisation of a random variable.
- Consider the concept of stochastic process to random functions with arbitrary inputs
where denotes the (possibly high-dimensional) input space. - With this, the function values
and for inputs are dependent.
- With this, the function values
- If we expect the function to be smooth (varies slowly), then the function values
and should be highly correlated if and are close. - This generalisation allows us to use random functions as priors for unknown functions in a Bayesian setting.
-
Start by making the simplifying assumption that
is discrete and can only take different values, . - The function is completely characterised by the vector
. - We can then model
as a random function by assigning a joint probability distribution to this vector . - In the Gaussian process model, this distribution is the multivariate Gaussian distribution, with mean vector
and covariance matrix .
- The function is completely characterised by the vector
-
Let us partition
into two vectors and such that and do the same thing for and :
- If some elements of
, say , are observed, the conditional distribution for then we can compute the conditional distribution of the remaining elements given is given as:
- The conditional distribution is nothing but another Gaussian distribution (with closed-form expressions for mean and covariance).
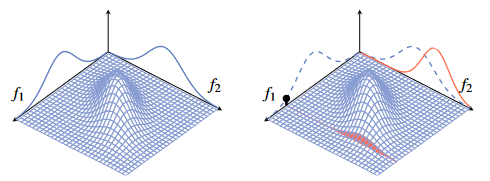
- In the figure,
is a scalar and is a scalar . - The multivariate Gaussian distribution to the right is now conditioned on an observation of
which is reflected on the right side. - Both of these Gaussian distributions have the same mean vector and covariance matrix.
- Since
and are correlated according to the prior, the marginal distribution of is also affected by this distribution.
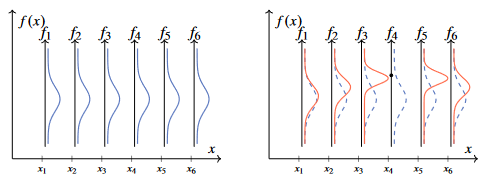
- In a similar fashion to the figure above, we can plot a six-dimensional Gaussian distribution.
- Assume a positive prior correlation between all elements
and which decays with the distance between corresponding inputs and . - We condition the six-dimensional distribution underlying the figure on an observation of
for example, producing the following plot:
- The extension of the Gaussian distribution (defined on a finite set) to the Gaussian process (defined on a continuous space) is achieved by replacing the discrete in dex set
in the figure above by taking a variable taking values on a continuous space, for the example the real line. - We then have to replace the random variables
with a random function (that is, a stochastic process) which can be evaluated at any for any . - In the Gaussian multivariate distribution,
is a vector with components, and is a matrix. - Instead of having a separate hyperparameter for each element in this mean vector and covariance matrix in the Gaussian process replace
by the mean function into which we can insert any . - Likewise, the covariance matrix
is replaced by the covariance function into which we can insert any pair and .
- Instead of having a separate hyperparameter for each element in this mean vector and covariance matrix in the Gaussian process replace
- From this, we can define the Gaussian Process - for any arbitrary finite set of points
it holds that:
- With a gaussian process
and any choice of , the vector of value functions has a multivariate Gaussian distribution. - Since
can be chosen arbitrarily from the continuous space on which it lives, the Gaussian process defines a distribution for all points on that space. - For this definition to make sense,
has to be such that a positive semidefinite covariance matrix is obtained for any choice of . - Let the following notation describe that the function
is distributed according to the Gaussian process with mean function and covariance function :
- Use the symbol
here for covariance functions as used for Kernels in the previous chapter - will soon discuss applying Bayesian approach to Kernel Ridge Regression results in a Gaussian process where the covariance function is the kernel function. - Can also condition the Gaussian process on observed data points.
- We stack the observed inputs in
and let denote the vector of observed outputs. - Use the notations
and to write the joint distribution between the observed values and the test value as
- As we have observed
we use the expressions for the Gaussian distribution to write the distribution for conditional on the observations of :
- This produces another Gaussian distribution for any test input
.
- We have abstractly introduced the idea of Gaussian Process.
- White Gaussian process has a white covariance function:
- This implies that
is uncorrelated to for any .
Extending Kernel Ridge Regression into a Gaussian Process
- We can use the Kernel trick from Section 8.2 to the Bayesian Linear Regression in Equation 9.11.
- This will essentially lead us back to Equation 9.21 with the Kernel being the covariance function
and the mean function being
- Repeat the posterior predictive for Bayesian Linear Regression (Equation 9.11) but with two changes:
- Assume that the prior mean and covariance for
are and . - This is not strictly needed, but simplifies the expressions.
- We introduce the non-linear feature transformations
of the input variable in the linear regression model. - Replace
with .
- Assume that the prior mean and covariance for
- Through this, we get:
- We use the push-through matrix identity once again to re-write
with the aim of having only appearing through inner products: - The push-through matrix identity says that
holds for any matrix .
- We use the matrix inversion lemma to re-write
in a similar way. - The matrix inversion lemma states that the following holds true for matrices with compatible dimensions
- We now apply the kernel trick and replace all instances of basis function inner products with the kernel.
- The posterior predictive defined in Equation 9.23a and 9.25 is the Gaussian model - it is identical to Equation 9.21 if
and . - The reason for
is that we started the derivation with - When we derived Equation 9.21 we assumed that the observed
rather than which is why .
- The reason for
- The Gaussian process is thus a kernel function of Bayesian linear regression much like Kernel Ridge Regression is a kernel version of L2 regularised linear regression.
- The fact that the kernel plays the role of a covariance function in the Gaussian function gives another interpretation of the kernel - it determines how strong the correlation between
and is assumed to be.
A Non-Parametric Distribution over Functions
- Use the Gaussian process for making predictions (computing the posterior predictive
). - However, unlike most methods which only deliver a point prediction
, the posterior predictive is a distribution. - Since we can compute the posterior predictive for any test point, the Gaussian process defines a distribution over functions.
- If we only consider the mean
of the posterior predictive, we recover kernel ridge regression. - To take full advantage of the Bayesian perspective, also have to consider the posterior predictive variance
. - With most kernels, the predictive variance is smaller if there is a training point nearby, and larger if the closest training point is distance
- With this, the predictive variance provides a quantification of the uncertainty in the prediction.
- To take full advantage of the Bayesian perspective, also have to consider the posterior predictive variance
Drawing Samples from a Gaussian Process
- When computing a prediction of
the posterior predictive captures all information the Gaussian process has about . - If we are interested in
the Gaussian process contains more information than is present in the two posterior predictive distributions and separately.
- If we are interested in
- The Gaussian process also contains information about the correlation between the function values
and - pitfall is that and are only the marginal distributions of the joint distribution . - A useful alternative therefore can be to visualise the Gaussian process posterior by effectively taking samples from it.
There is some further content on the practical aspects of the gaussian process which I have omitted